
Here I summarize what you should expect from core aggregator for Drupal 7.
Specification
User-side
- RSS, RDF, ATOM feeds
- feeds and feed items = nodes by default
- input formats for sanitizing feed item content
- per-content-type settings
- categorization of feeds and items
- summary block for feeds and categories
- OPML export, maybe import too.
- no need to tune time interval for feeds (smart cron part)
Developer-side
- parser and processor (hooks and data structure) support for extending the capabilities of the core aggregator
- SimpleXML (Drupal 7 = PHP5 only)
- full simpletest test set to find out immediately if your patch is not good enough :)
- The data structure that is provided between aggregator and parsers, processors will be available soon
stay tuned, will be extended
Design
Components
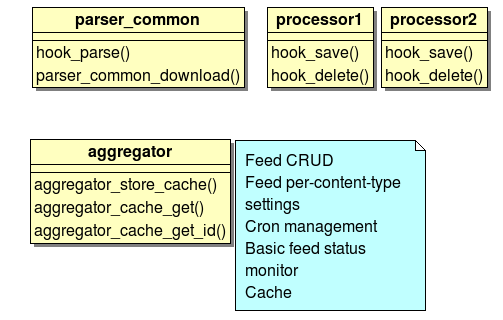
It's according to the tree structure. (http://groups.drupal.org/node/11409)
It's really important that if the aggregator is turned on, parser_common is always available. So all other contrib parsers can user its downloader functionality (or pre-parser too). Other: one content-type configuration can contain one parser and one or more processors. This makes the aggregator module easier, because there is no need to union the result.
Flow of an update
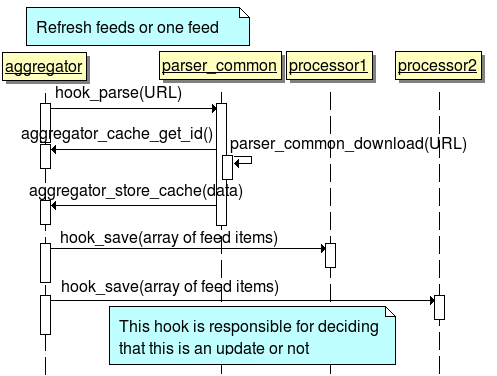
In the processing of a feed, only one parser can involve in. (and it may re-use some parser_common downloader and parser capability). But a contrib parser can fully replace parser_common in the configurations.
The hook_parse accepts an URL. This URL also contains authentication data, so it's not important to provide additional UI for this.
The hook_parse handles all type of redirects that aggregator will support.
The hook_save returns with statistics: how many new items / duplicate items / success of item save and so on.
The processors cannot see each other's result in an obvious way. (it's the tree structure, not the pipe)
Data structure
Item structure, possible output of a hook_parse() :

The design is being improved continuously. These are just the rough drafts.
| Attachment | Size |
|---|---|
| components.png | 29.8 KB |
| update.png | 25.65 KB |
| item.png | 18.43 KB |
{kind=link}
{kind=link}
{kind=link}
Comments
-1 from me, solely because
-1 from me, solely because of feed items as nodes.
There's a huge conceptual difference in the three main case scenarios:
As a consumer, there is very little need for feed items as node - the user is utilizing the aggregator.module as a replacement for a desktop (or otherwise web-based) client application. Feed items are deleted as soon as they are read, and the user doesn't care about commenting, storing, or categorizing the feed items. The consumer may decide to share his consumptionary habits with his site's users, but doesn't want them to be bookmarkable or potentially permanent or damaging to the internet (all side-effects of feed items as nodes, especially when the URLs would be pruned/deleted after consumption).
For a producer, the role is reversed: the RSS feeds added to the site are generally made public and intended for the site's users to consume. This consumption entails permanence or categorizing or subscribing or commenting or rating, etc. Nodes would be required and powerful here.
Then there is the mix - the site admin is a consumer because he has feeds that he wants to consume and nothing else (thus not needing the capabilities of a node) but he also has feeds he wants to produce - say, importing his items from his myspace.com page into Drupal. This case scenario requires the choice of node-or-not to be made per feed - some feeds are imported (because their value benefits from being nodes) and others are merely consumed.
Here's two literal examples:
I want to subscribe the critical issues queue to Druplicon, the bot that lives in #drupal. Whenever a new item appears, the bot spits it to #drupal and #drupal-dev. Since disobey.com, however, is primarily NOT a Drupal showcase, and has readers who don't give a crap, the feed items are consumptionary only - they are not meant to be permanent, to earn a URL, or to otherwise be nodes.
On the other hand, disobey.com is a mass producer of content, and has a number of other sites under its wings. I would like to import feed items, as nodes, from gamegrene.com, drupaltoughlove.com, and so forth, and have them permanently available with URLs, comments, etc., etc.
Good examples
I agree with you on the importance of the use cases you describe.
If I understand you right your argument is less on the basis of "feed items should be their own record, not nodes" but more along the lines of "don't lock us into nodes as feed items - think of non-content aggregation" - ?
The new aggregator should support both scenarios - permanent aggregation and temporary aggregation (e. g. the first literal example you gave) and I see that Aron's post here is not entirely clear on this.
The question is which configuration should ship with core: I lean towards feed items as nodes as
a) the core aggregator use case will stay a permanent aggregation use case (expire items or not)
b) categorization with nodes as feed items + taxonomy can be done in an elegant and compatible way (see comments here: http://groups.drupal.org/node/9857#comment-31087)
c) with feed items as nodes a range of other features come out of the box.
d) performance disadvantage of nodes starts to hit at a point where more serious tuning of aggregation pipe is necessary anyway and site builders can be bothered with a switch to a more performance tailored contrib module.
http://www.twitter.com/lxbarth
RE b: currently, the core
RE b: currently, the core aggregator has its own set of categories that are separate from taxonomy -- this is an unnecessary and confusing duplication that feed items as nodes addresses.
With that said, doesn't the current setup of the feedapi already allow (or come close to it) for both of these scenarios? IIRC, the feedapi aggregator module come close to behaving as Morbus describes? From the description, it sounds like it:
Cheers,
Bill
FunnyMonkey
Tools for Teachers
FunnyMonkey
Alex: unfortunately, your
Alex: unfortunately, your comment largely comes down to forcing existing users to switch sides. All the users of core's aggregator.module (which, for the lack of actual data usage, let's assume is "more than contrib") are now forced to use a contrib module, and all the users who used items-as-nodes contrib modules can now bask in the glory of doing it in core only. To make matters more confusing (and, imo, slightly retarded), the only current implementation of "core's way" in contrib is the FeedAPI module which is the precursor for this core work and would largely become irrelevant once and if this module became core.
I don't believe there /is/ a question of "which configuration should ship in core" - I don't think that question has ever been asked (again, we go back to the fact that there's never been any writeups on how people actually use aggregator.module). As far as I can see, there's just been this blanket assumption that "nodes give us more features, therefore, they must be better". That's not always the case.
Yes, you could say my argument is "don't lock us into nodes as feed items", but my argument is /more accurately/: core should do both. There's no reason, with FeedAPI being the unspoken "trial run" for this "for core" project, that core couldn't ship with both feed items as nodes and feed items as Other, especially when there are clearcut use cases for both scenarios, and especially when core has been doing it the Other Way since time began.
I'm not arguing against feed items as nodes (though, I certainly could: linkrot still remains a huge concern) - I'm arguing about feed items as nodes being the only implementation in core. I don't care if the API allows me to do items as Other outside of core - I want items as Other in core, alongside items as nodes.
Let's skip the core config question
"The question is which configuration should ship with core: I lean towards feed items as nodes as" -- let's skip this for now. That configuration would be done in the default.profile --- and currently, aggregator is not turned on and not configured out of the box.
Let's agree that the core aggregator shipped with Drupal should support feed-items-not-as-nodes. This is one module and should have all the functionality in one place, and could be specced by Morbus as I said below.
Agree with Morbus. Feeds as
Agree with Morbus. Feeds as nodes yes -- feed items as nodes should be optional.
The one implication of this is categorization of feeds and feed items. Feeds can use "regular" taxonomy norms. I see the non-node feed item functionality being all in one module -- this could include a small bridge to taxonomy, or build in some light weight categorization directly into that module. I bet Morbus has some opinions on how to do this :P And yep, input filters would also need a small bridge to these non-node feed items, although I see that as being a processing pipeline where filters and hooks need to go anyway.
I'd like to see OPML import as well (and yes, this would be easy to do as an add on, but if you're doing export already, then import would be interesting, too).
Morbus -- would you be willing to spec the non-node feed item architecture? including these bridge modules (or choose to punt on some functionality -- e.g. no categorization unless you use nodes....).
I've been rocking back and
I've been rocking back and forth between "I'm OK with losing categorization for items as Other" vs. "Nah, it should be as feature-complete as items as Nodes". But, then again, the argument seems to be "currently, aggregator.module invents it own categories" and the solution seems to be "woot, let's switch to nodes!" as opposed to "erm, fix aggregator.module to use taxonomy", which isn't hugely difficult either (it's less difficult, IMO, then switching to nodes).
The biggest problem, however, is end-user display. Do Other items with Term A get displayed alongside nodes with Term A when taxonomy/term/34 is displayed? (My opinion: No, I don't think so, but I can see rationale why they should.) Can Other items share the same vocabulary with Node items? (My opinion: yes.) If Other items hook into taxonomy, should the taxonomy API be modified to support retrieval of non-node items? (My opinion: sure, but now we're getting dangerously into "taxonomy.module sucks too" territory.)
As for "spec'ing the non-node feed item architecture", I don't find a need for that - as stated in my previous comment, largely the API here is based off FeedAPI, and FeedAPI has already implemented "items as Other". It'd just be a matter of building the taxonomy bridge (which I don't know if FeedAPI currently does or if it retains the invented categories).
Displayed alongside other
Displayed alongside other Taxo node items: no, use Nodes.
Other items share vocab: yes.
Taxonomy bridge: yes. Does taxonomy suck: yes.
FeedAPI currently doesn't do categorization for those Others, I don't think.
By "spec'ing", I mean doing what we're doing here :P on what's in or out. So, look at feedapi_aggregator, and see what else you want from it (if anything), and what needs adding or fixing.
And another aside. Currently, the Feed API UI is complex. To be core worthy, it needs work. I have some rough notes on this (as I'm banging on it heavily at the moment).
UI too complicated
Yes, the FeedAPI UI is too complicated. I don't think the core aggregator's UI should look like it. Would be curious to see those notes...
http://www.twitter.com/lxbarth
Themability
categorization, input filters and: themability: if feed items are nodes we could theme them the same way as any other node.
http://www.twitter.com/lxbarth
If node and non-node storage
If node and non-node storage are both offered in core (which seems like a decent option to me), then it also seems fine to say 'if you want categories, use nodes + taxonomy' - since the option is there.
Another option would be to have the bridge module in contrib if that was doable - aggregator_taxonomy or whatever. Looking ahead, I'd rather see fields in core/data-API take care of attaching taxonomy to non-nodes (and everything else) - even if that has to wait for D8/9 (then the contrib aggregator_taxonomy just provides an upgrade path when that happens).
Feed items should not be
Feed items should not be nodes by default. I'll support having the option to make them nodes but not by default. I'm using aggregator because I didn't want my feed items to be nodes and every other contrib module wants to the make them a node.
Something I don't see addressed here is sorting. At present, the aggregator module sorts by timestamp descending. It would be nice to change the sort column / order. Since I have a need to make this happen in my own stuff I've already started working on a patch for 6.x and was preparing to build a patch for 7 until alex_b referred me here.
Hi darthclue, what caused
Hi darthclue, what caused your decision to not use nodes as feed items?
Was it performance considerations?
In regards to sorting: as far as I understand, views 2 supports operating on other entities than nodes. Have you considered integrating aggregator records with views 2?
http://www.twitter.com/lxbarth
Who cares?
There are clear use cases for nodes not as feed items. Current core supports it, and this would also provide a nice upgrade path. Let's stop questioning the use cases, make a split between functionality, and go from there. feedapi_aggregator already provides this, so I don't really see the issue.
I'd still like the know the
I'd still like the know the reason why feed items should not be nodes from a user. As mentioned earlier, nobody has any concrete use information for aggregator.module past and present. This might be one piece of information we could know instead of second guessing.
Just saying "because nodes are dirty" is a pretty stupid excuse too.
I'm still not clear why feed items as nodes "behind the scenes" is a problem either. Link rot, hmm, just don't link to an individual node when themeing the output?
Erm, I gave concrete
Erm, I gave concrete examples as the very first comment on this node, along with user archetypes. No one's suggesting that "nodes as items" should be removed entirely. Nearly everyone is suggesting that the module does both.
"Link rot, hmm, just don't link to an individual node when themeing the output?"
That puts the onus on the user to prevent link rot, which is exactly the reason why we have link rot today.
I don't think it does put
I don't think it does put anything on the user. If the modules default theme functions render the nodes to not display any node specific links then nobody is the wiser. A developer can override the display of feed item nodes if they so wish. Or is there some other link rot you have in mind?
This means you don't have the maintenance hassle of two storage methods in the core aggregator system, and can concentrate efforts on more important things than database storage of feed data.
As for concrete examples in your first post, I see no concrete reason why aggregator items are any better to use than a node when storing the feed data.
Feeds as nodes just seems
Feeds as nodes just seems dirty. I don't see a need to have feed items as nodes. Core doesn't do it now and forcing me to do that in the future would most likely result in a module that let's me keep the old way. Nodes, to me, are a more permanent type of content versus something that really isn't even my content. I'd be very happy to see an option to not store feed items at all. A feed should be considered volatile information and treated as such. It shouldn't be stored / cached unless performance is an issue.
And why would I want to introduce something as large and complex as views for something as simple as sorting? Really, why?
Not that I don't agree that if the wheel exists it shouldn't be reinvented but last I checked, on Friday, I didn't see any way to use Views or Views 2 to sort feed items.
At this point, I've got a patch ready for 6.2 that I'll be making available today for those interested in sorting feed items.
Views 2..
.. allows you to specify any table as a base table. So although core aggregator items might not be implemented yet, it should certainly be possible to do so - I say this never having looked at the core aggregator schema.
Feeds as nodes offers options for actual syndication of content between different related sites, and maybe full blown import of content from other systems, where the feeds really do want to be permanent. I agree that when aggregator is just used as a web based feed reader then this shouldn't be the case though. I can see valid use cases for both (and within one site too).
Feed items as nodes open up
Feed items as nodes open up a whole world of extra possibilities - allowing feed items to be voted on, printable with the print.module and everything else you get with the Drupal node api.
The traditional feed items need to have individual support added to make them do anything interesting. Why maintain two methods of sorage in the database when the node API is perfectly feasaible?
You can still set the lifetime on the feed item nodes to be deleted later on, I don't understand what the deal is with nodes being used for short term content either?
A lot of people user feed aggregation to build up an archive of material from an RSS source.
Both methods should be implemented as part of SoC project
Given the arguments brought forward on this thread I think Aron's SoC project should implement both methods of aggregation - node based and 'lightweight record' based.
Apart from these two ways of aggregation there should be a way to use aggregator not to actually aggregate content but to process it without storing more than the information to identify what's been processed and what not (this needs to be explored further).
These functionalities will be implemented in a pluggable way, so if there's the need to implement aggregation to more exotic storage forms there should be a clear and simple way to do that.
The decision of what goes into core and what not can be done later based on the code we're looking at. I'm still in favor of doing either the one or the other, because it is the simpler solution and the overall code base will be smaller. I'd like to emphasize that while Aron and I have been working mostly on node based aggregation solutions, we're not advocate of using principally the one nor the other. The suggestion here was merely to use aggregation as node items for core as a flexible solution while leaving other forms of aggregation up to contrib modules.
Clearly, there is no agreement on this suggestion.
And actually there doesn't need to be one in order to move forward: I'd suggest to drive both methods to their best for this project and I invite everybody with a stake here to have their eyes on the outcome and help with constructive input.
Once we have the entire package to look at, let's decide whether to divide it up and, if so, which functionality to ship with core - this is a discussion to have at an entirely different point in time, not at least because core worthy code is yet to be produced.
http://www.twitter.com/lxbarth
On twitter / update to come soon
Aron's tweeting his progress on http://twitter.com/aronnovak , I'm throwing in thoughts on http://twitter.com/lx_barth - follow us!
Aron's working on a revision of this draft right now, expect an update soon.
http://www.twitter.com/lxbarth