Project information
Student: Arjun Kapur
Mentor: Matt Chapman
Co-mentor(s): Thomas Narres
Current status: This module has been published: https://www.drupal.org/project/mltag
Description
The idea is to implement an auto tagging feature that provides tags automatically to the user depending upon the content of the post. The tags will get populated as soon as the user leaves the focus on the content text area or via ajax on the press of a button.I’ll be using semantic analysis and topic modeling techniques to judge the topic of the article and extract keywords also from it. Based on an algorithm and a ranking mechanism the user will be provided with a list of tags from which he can select those that best describe the article and also train a user-content specific semi-supervised or a supervised machine learning model in the background.
Project Link
Drupal Sandbox
Original Proposal Link and Project Schedule
Schedule and Updates
Before 21st May
In this period I’d like to discuss my idea with the mentors, take feedback from the community and do the necessary changes to the idea. Since, the project is heavily into semantic analysis which is currently a hot research topic and involves NLP, Machine Learning, so I’ll utilize this time for discussion with Professors in this field to come up with the best solution. Also, familiarization with the Drupal coding standards, study of documentation are on the line.
May 21 - May 31
Further Research into ML models, their implementation details, data-structures used etc. -
Classifiers- SVM, Naive Bayes, Decision Trees.
Instance based learning- SVM, k-NN
Clustering (Unsupervised) - k Means, Probability based Clustering, Incremental clustering.
Semi-supervised- EM and Co em
Setting up development environment
June 1- June 10
Implementation begins
Sandbox Project up and running
Implement basic configuration pages for project
Simple Ajax front end for nodes - Add article and Basic Pages
Implement Pre-processor for textual content. This includes classes-
1.Tokeniser
2.Normaliser
3.Stop words removal
4.Stemming
June 11- 15
Find the suitable corpus to be used as a training data set for the model.
Plans are to use user's past posts as a data source for training the learning algorithm -in case a suitable corpus is not found.
June 16 - June 23
Implementation of the classifier code
Plans are to have a vector space model ready initially as a backdrop algorithm.
Configuration Pages alteration for the vector model.
Classes for - weights calculation, vectorization etc.
June 24- June 30
Code similarity class - cosine similarity or adjusted cosine or correlation based similarity.
Code for upgrading and maintaining the learned vocabulary set.
July 1 - 10
Start work on another classifier algorithm after consultation with the mentor. The plan as of now is to have a working prototype ready by mid-term evaluation and later on work on incorporating additional models/algorithms, which the user can choose from that best suite his needs.
July 11- July 31
Coding of new classifier, do improvements-optimization and cleanup, changes based on feedback received during mid-term evaluation.
August 1- August 10
Complete documentation and any other pending work.
Final Submission
At the end of the final submission we will have a complete working module with the auto tagging feature implemented.
| Attachment | Size |
|---|---|
| Basic_activity_diagram.jpg | 53.99 KB |
| word_coccurrence_statistical_algo.jpg | 40.66 KB |
| learning.jpg | 69.26 KB |
{kind=link}
{kind=link}
{kind=link}
Comments
for the drupal integration
for the drupal integration part, you could leverage http://drupal.org/project/rules_autotag
@dasjo -thanks man ill surely
@dasjo -thanks man ill surely look into it..
great. i'm co-maintaining the
great. i'm co-maintaining the module, feel free to ping me on IRC if you need something
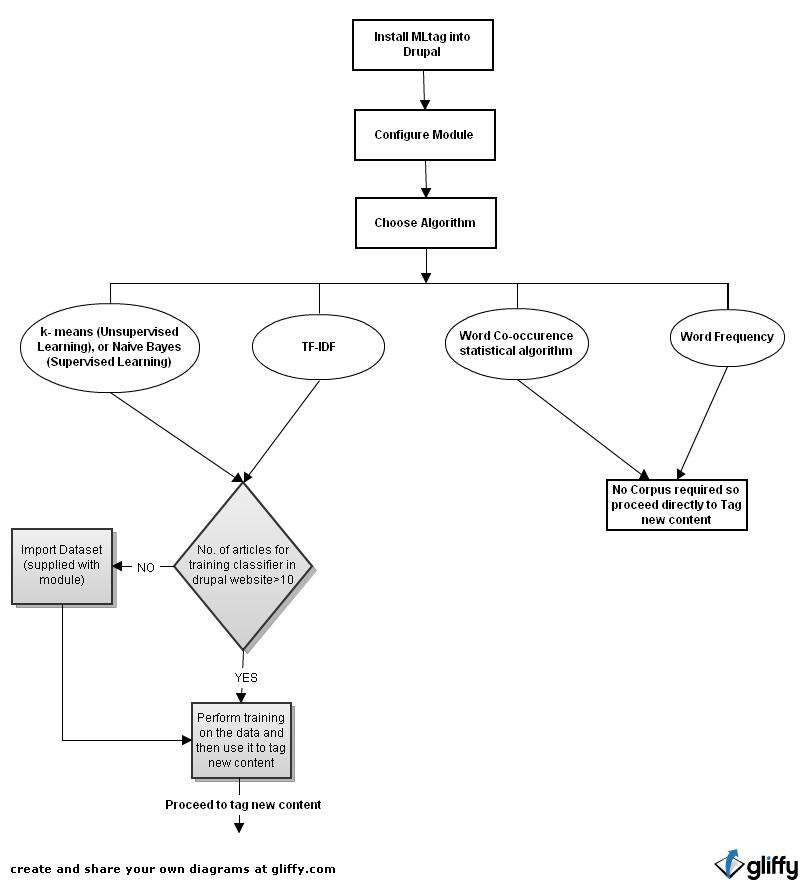
word co-occurrence stat algo ready
The word co-occurrence statistical algorithm proposed by Y. Matsuo and M. Ishizuka - http://bit.ly/N9xyn2 has been implemented in the module.
The amazing fact about this algorithm is that it applies to a single document for keyword extraction without needing any corpus ! It uses chi square value to judge the importance of every term in the text.
Steps- go to MLTag config page -> choose algo type -> Word co-occurrence algo -> Save configuration
A flowchart attached by name - word_coccurrence_statistical_algo.jpg
The implementation does not cluster the terms at present, the main goal of which is to reduce the matrix sparseness and has been left as a future implementation.
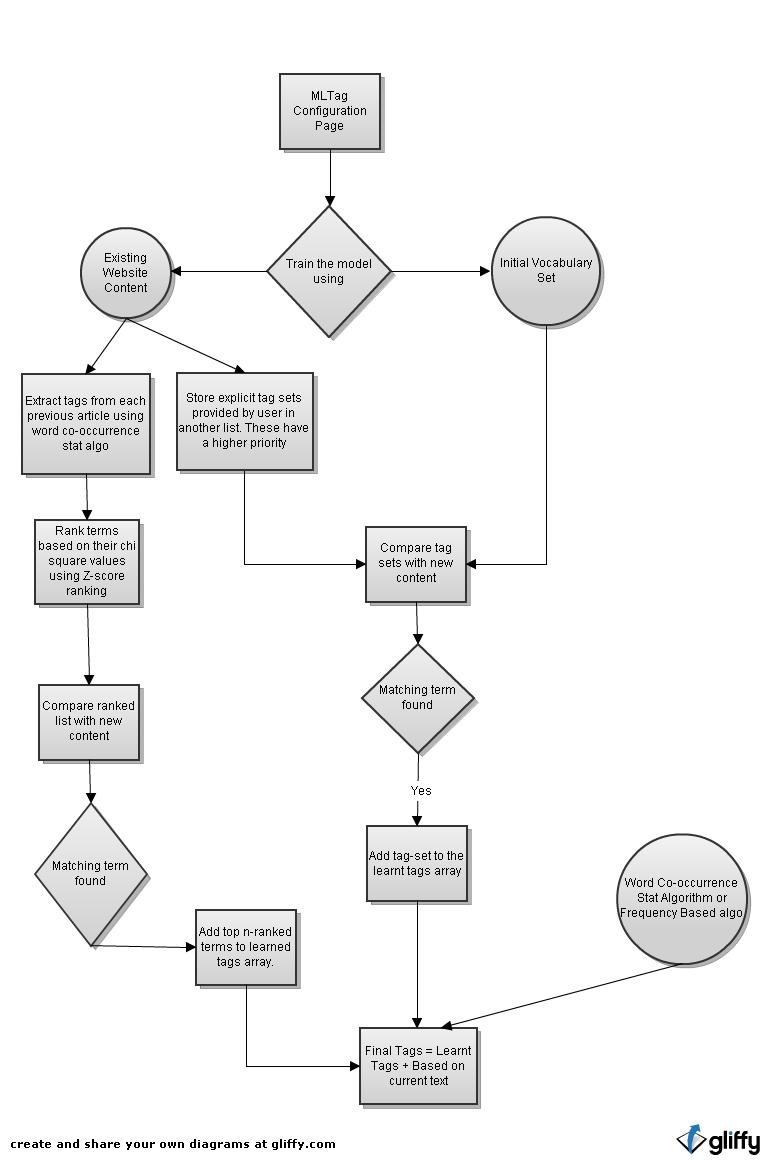
Learning algo ready
An algorithm has been implemented for training a model that learns about user's past tagging patterns and posts on the website and then proposes tags for the new content based on that.
The algorithm follows the flowchart attached as - learning.jpg
The greater the amount of pre-existing training content, the higher will be the accuracy of the algorithm, to propose tags based on the learned vocabulary. Also, the accuracy will be higher when the model is trained regularly and kept up-to-date.
To perform training - Go to MLtag settings -> enable learning -> perform training -> Confirm action.
Now post new content -> click on Suggest tags -> displays learned tags along with tags based on current content.
Taxonomy module Integrated
Added the feature to select vocabularies defined by the taxonomy module to add to the trained model.
Steps - go to MLTag config page -> select the checkboxes next to the vocabularies that you want to add -> Save configuration
Project Screen-cast
Screen-cast for this project can be viewed at- http://youtu.be/kZ3s_N5Qv4g