
Posted by ademarco on May 18, 2009 at 8:57am
Hi all,
I've been working on an add-on module for Feed Element Mapper that extract content from raw HTML contained into syndication feeds. It is called Feed Scraper, here its project page: http://drupal.org/project/feedapi_scraper.
As you can see from the screenshot it uses xpath queries to scrape out the information you are interested in. It allows to plug in other parsers as well, a regular expression one is already available with the module.
After defining a set of scrapers you are then able to map them to CCK fields using Feed Element Mapper. Since I've just released the first dev version every feedback, comment or feature request is really welcome.
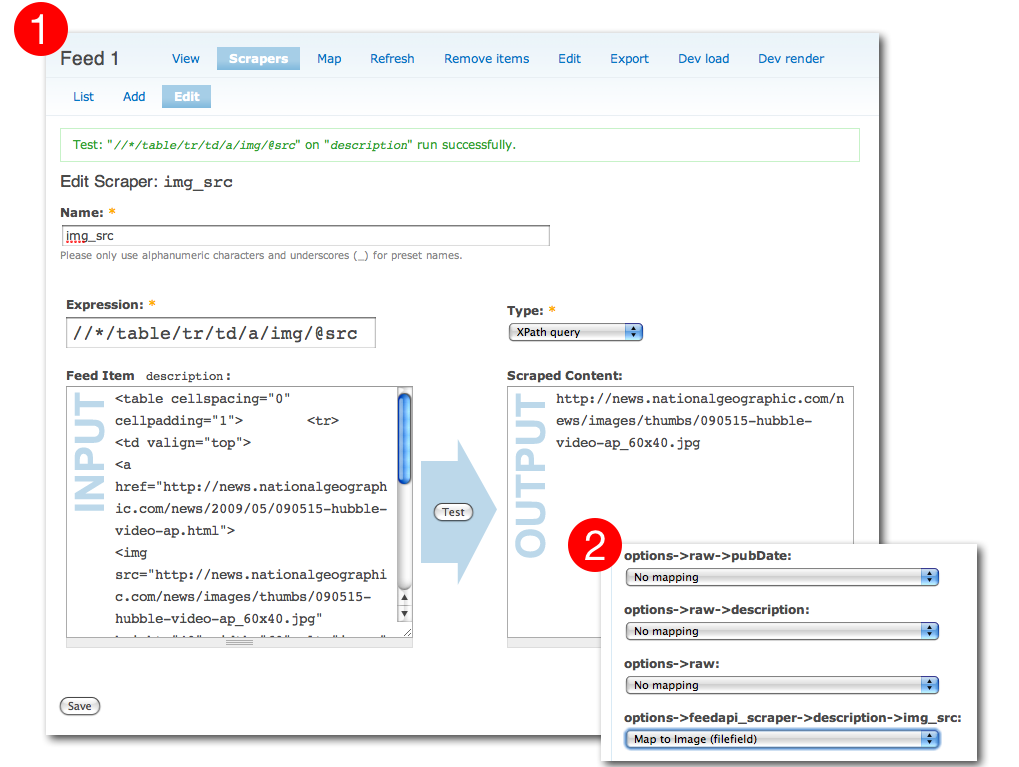
| Attachment | Size |
|---|---|
| feedapi_scraper.png | 125.59 KB |
{kind=link}
Comments
Hi, Looking great this
Hi,
Looking great this scraping!
Would it be possible to automate some things, may be getting out the scraped content by rules or something?
Thanks for considering this.
greetings,
Martijn
Hey Martijn, what do you
Hey Martijn, what do you exactly mean by "getting out the scraped content by rules or something"?
This is the future
Antonio -
Sorry for the late reply here. Just ran into your post again and found the time to review this module. This. is. great. stuff.
In fact, I think this approach should be at the core for a next generation XML parser for FeedAPI.
Ideally, such a new parser should not have any hard coded rules on which elements to retrieve from the XML document, but it should have a configurable set of XPath based rules that can be modified and expanded by a tool just like FeedAPI scraper. There are some questions to be solved around how to implement fallbacks in case of malformed feeds, but I think there is a strong need for the flexibility of such a parser.
What are your thoughts? What are your plans?
http://www.twitter.com/lx_barth
http://www.twitter.com/lxbarth
Hi Alex, I absolutely agree.
Hi Alex,
I absolutely agree. We ran into the need of having a more flexible FeedAPI parser when we had to aggregate and map content exported from different Drupal distributions spread around Europe where most of the information is available into well-known CCK-generated HTML structure. For the moment I haven't consider the case of not-well-formed feeds, but this is surely an issue that must be addressed before to release a stable version of the module.
I think possibilities are really interesting. For example: imagine to have an online scraper repository where people can share their expressions covering the most known XML syndication formats out there: we could instruct the module to automatically provide the administrator with a list of scrapers from that repository, in this way if, let's say, Flickr changes the HTML of its feeds, it will be enough to update the repository and all the websites will continue to work. We could also think about an automatically diagnostic tool that will alert the repository maintainers (or the scraper author) in case one of the scrapers continues to fail. Then of course you still have to be able to create your own scraper in the way we do now; In this case the next step would be, once that your expression has been validated, that the module will ask you: "It works! Do you want to share this scraper?" (linking to the repository). Also, I wanted to extend the module to allow it to scrape not only XML feeds but also generic HTML pages, it could have some nice application as well.
Another nice feature would be to implement an automatic way to generate scraper expressions. The module should just present the feed XML to the end user and, with some jQuery trick, the user will just have to select which peace of content he wants to extract and the module will automatically generate an expression out of it; it is feasible and it will lower a lot the technical requirements necessary to actually use the module: knowing how to write xPath/Regex expressions. As a short term plan I also want to integrate the module with Features (to make the scrapers exportable).
This are some of the ideas I have in mind, I'm looking foreword to knowing what you think about them.
mini-tutorial
For those interested: I have published a mini-tutorial in reply to Need some help, here the link: http://groups.drupal.org/node/24472#comment-84916
Hi, I suggest you to try
Hi,
I suggest you to try with the latest version of the module available online since today. Anyway, this is not the place for support requests, the right place to post such an issue is the module issue queue here:
http://drupal.org/project/issues/feedapi_scraper
Please, report it there too, it will help me with the module maintenance.
Thanks!