
From what I've been able to gather, one of the two major use cases that WSCCI is targeting with its JSON-LD support is deployment.
I've been having a little trouble wrapping my head around how we want deployment to work. In this post, I lay out my understand of how it could work, some of which exploits the Linked Data part of JSON-LD. I'm hoping that those involved in developing deployment can help me understand if/where I've got it wrong.
I've drawn this up as a UML activity diagram, with different streams for the following actors (left to right):
- Site admin on Source Site
- Drupal instance on Source Site
- Drupal instance on Target Site
- Site admin on Target Site
If you can't read activity diagrams, I've written out a translation below, or you can take a look at Agile Modeling for a quick explanation of the notation.
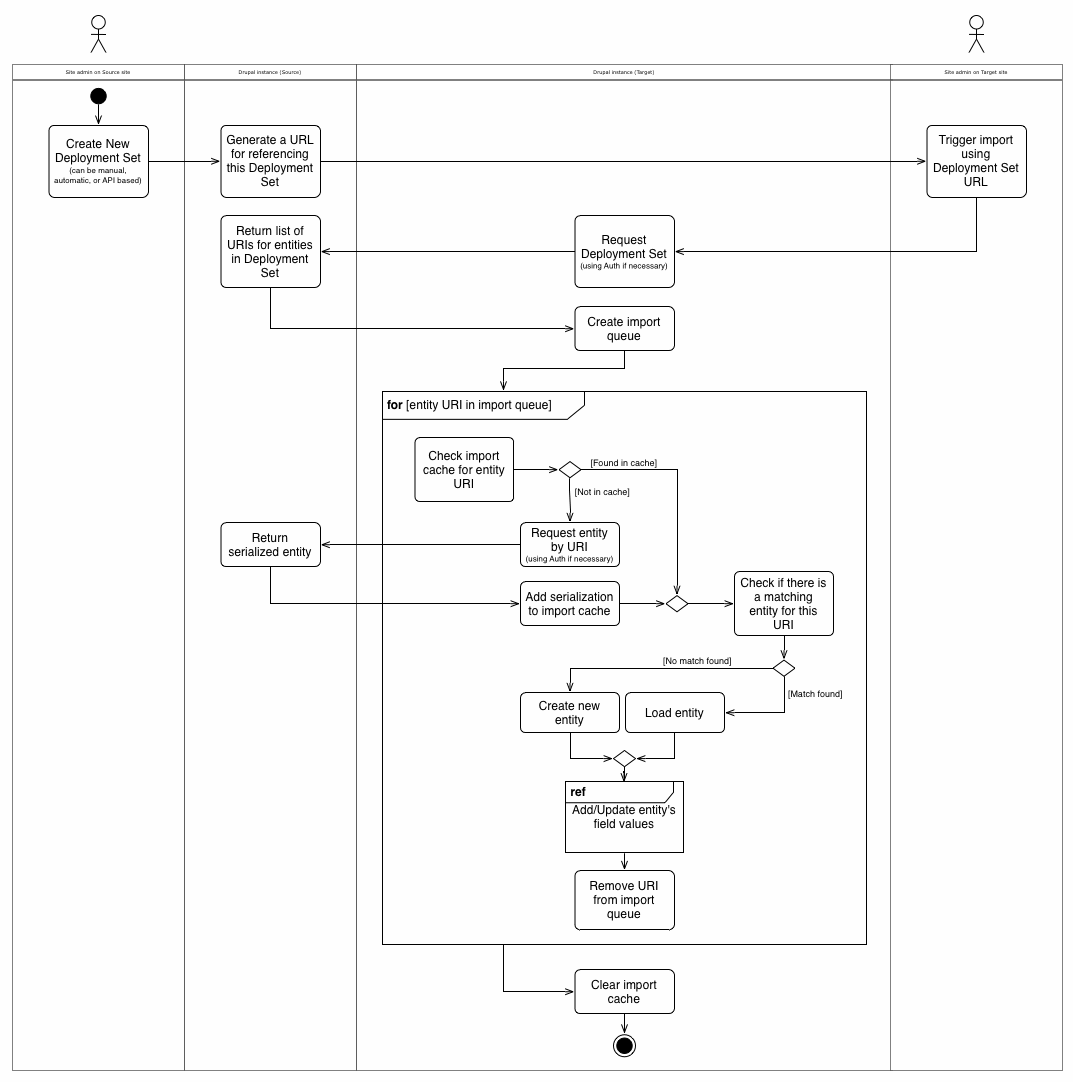
Diagram translation
The admin on the source site creates a deployment set, and the system creates a URL for it. The admin can then go to the importing (or "target") site and enter that URL. The target site will then go to that URL to get a list of entity URIs.
The target site will then iterate through the entity URIs to add each entity. It starts by seeing if it already has the JSON-LD for the entity in its cache (this could happen in the case of entity references). If it doesn't, it gets the JSON-LD from the source site. Once it has this, it will see whether there is already a corresponding entity in the system. If there isn't, then it creates one.
Once the entity is loaded/created, add the fields. I leave this to be detailed in a future diagram because there are a lot of separate discussions that need to happen around that.
Once all the fields are added, the entity's URI is removed from the queue. Once the queue is empty, the cache of serializations from the source site is also emptied.
Discussion/Confirmation needed from deployment developers
There are a few points which I want to draw attention to.
- Deployment sets
-
Basically, this is the entity part of deployment plans. It's a set of URIs that should be imported/updated. I would see three ways of creating these
- Manually, by checking off the entities via a UI
- Automatically, by adding all entities of a certain type
- via Queryable API, allowing the target site to pass in parameters like "updated since DATETIME"
Does this make sense?
- Matching entities from source to target
- We need to consider how we are going to handle this... specifically, whether we are going to have the UUID in the URI and then parse it out or whether we just store the full URI from the source site and matching based on that. I lean towards storing the source's full URI.
- Dependencies between entities
-
When using entity reference fields, you don't just need the content from the entity itself, but you also need the content from the referenced entities. This would take place in the "Add/Update entity's field values" part of the process (which I haven't diagramed yet).
Since we're using Linked Data, I would suggest that, in the JSON-LD serialization of an entity, the entity's reference fields only contain the URIs for the referenced entities (and possibly the title field value). That URI can then be added to the import queue and used to retrieve the rest of the data about the referenced entity.
| Attachment | Size |
|---|---|
| Deployment-20120806.gif | 37.82 KB |
{kind=link}
Comments
Thanks for taking the time to
Thanks for taking the time to put this together!
This is reasonably close to what Deploy does, with the difference that Deploy uses a push mechanism (this is a pull mechanism if I read things right.) In general, I found that clients preferred this workflow. I also used to regularly get requests to not have to generate plans in order to deploy, for instance 'Whenever a node of type x is published automatically push it to server y". However, ultimately, I think that kind of thing is more of an organizational detail and less important to the problem at hand of how stuff moves around in the first place.
I agree.
I also agree with this. I don't even like storing the title honestly.
The dependency stuff is extremely complicated, and it was by far the most difficult part of Deploy. I tried several times to diagram it, and always ended up with a mess. There are two aspects of it that really need to be considered.
1) Some types of data need to always exist before other types of data. For instance, user entites need to exist to be able to create any content entites in order to properly attribute authorship. Taxonomy generally also needs to exist before content entities. There is no good way in Drupal to represent this hierarchy, in Deploy I just hard-coded a weighting mechanism that worked most of the way but wouldn't handle a lot of contrib use-cases.
2) Even getting past that, just pulling in all the dependencies is pretty complicated. You have to recursively grab the linked entities, and then scan them for THEIR linked entities, and on and on down the chain. These entities are added into the plan weighted 'lighter' than the item before it (to guarantee they get deployed before the entities that depended on them.) You also have to detect circular dependencies or you get in a loop. This new system will have an advantage in that you will be able to tell in the serialized data which properties are references and which aren't. I never had that option and had to add in a hook system that modules could respond to in order to manage this.
Because of all this, the deployment process in Deploy actually happened in two steps. The first step went through the dependencies, grabbed all the referenced data, and added it to the plan in a properly weighted table. Then the second step actually deployed this data in the proper order. You'll notice above there is actually two levels of weighting, type weighting (users need to deploy before nodes) and entity weighting (node 4 needs to deploy before node 5 because node 5 references node 4). Doing this all in one step is something I never figured out how to do and I'm not sure its worth the effort.
Oh also, if anything specifically references the serial IDs, those IDs need to be updated on the fly as the deployment happens since they may be different from site to site. So while we are keeping serial IDs for a lot of use cases, things like entity reference fields should ideally use the UUIDs. THis breaks a lot in Deploy. For instance, embedded links to node/nid URLs will always break. Pathauto is a requirement (although is we go to UUID-based URLs we are basically saying that anyways I think.)
Three years of research and coding distilled in 30 minutes of typing :) I would love to talk about this more in Munich, I think at the very least a BoF is in order. I am trying to get some sponsorship for CMI and one of my priorities is getting back involved in the content staging issues. I always intended this to be part of CMI and I never had the time to track it.
Another thing to think about is bringing along linked data that is not entities. For instance, a file or image node will reference an image on disk. This image will in many cases not exist on the remote server.
migrate module
I hope folks have read the WSCCI Paris summary as that details our plan for entity references.
This discussion relates to our work on migrate module. We also try to order migrations so that users come before nodes and so on. But you can't easily do that when a story node references another story node. In the thornier cases where referenced data does not yet exist, we simply create a stub entity as we need it. We now have a nice entity_create() function in core. The stub entity would presumably have the right UUID and a placeholder title and thats it. Migrate marks the stub entity as 'needs update' in its map table, but that might not even be necessary here. If we know that the referenced entity is in the deployment set, we just wait for it to show up in the set and perform an update then.
That is why I came up with
That is why I came up with the two-step process in Deploy. The stub option works too, I used that same method for managing circular references. Since the actual deployment part isn't going to be in the cards for D8, I suspect we'll see lots of other methods crop up in contrib too, which is great because we can use them to inform D9.
Support a secondary use case?
So I had a secondary use case in the back of my mind when writing this up... when you are "deploying" from a site outside your production stream or from something that is non-Drupal. These are use cases that are common with tools like Feeds and Migrate.
An example would be if Drupal.org wanted to pull in a catalog of tutorials from sites like NodeOne and Lullabot. I explain how this could be done with microdata on IBM developerWorks, but JSON-LD would be better. Basically, Lullabot would create a deployment set that just contained their tutorials. Then a *.drupal.org site could be pointed at that (with auth if necessary) and maintain the listings in the catalog.
I honestly haven't thought through this secondary use case enough to figure out if it makes sense to support both it and deployment with the same tool or not. However, I do think it is worth having a discussion to decide if we can create one generalized system that supports both... and if we can't, specify what the differences are.
heyrocker said:
I structured this as a pull so that content could be "deployed" without the source site having node creation privileges on the target site. I think this makes the secondary use case easier, since you don't necessarily want to trust the developers of the source site with the necessary privileges... but we have to consider whether the ease of use for deployment that you describe trumps that. Or we could potentially support both push and pull.
scor said:
I wasn't suggesting that you would switch the prefixes, since URIs should be opaque. Instead, I was suggesting that we store a "sameAs" property. This would allow us to say that http://staging.site.com/node/1 is the same as http://live.site.com/node/5. Then, when we pull in an imported entity with the URI http://staging.site.com/node/1, we could do a lookup on the sameAs column and see that it matches our node/5.
I haven't fully thought through this approach, so there may be holes. However, I believe it would allow us to support deployments/migrations from other systems that don't have the same UUID support that we do.
I structured this as a pull
Yeah this was definitely an issue I had with Deploy, and I never had a good way around it. Anyone doing deployment had to have the username and pass of a user on the remote site with administer nodes (and possibly taxonomy, users, etc.)
Ultimately, I think we will be able to support a lot of different workflows if we just provide the proper plumbing. If we have solid resources for reading data, saving data and authentication, then people can put together all sorts of workflows.
We need to consider how we
How would the match happen if full URIs are used? are you assuming that the target site has its entities mapped to their source URIs somehow? How would http://source.example.com/node/431b5ec5-0f9f-2c04-7d0f-232daed9251e get mapped to http://target.example.com/node/431b5ec5-0f9f-2c04-7d0f-232daed9251e without either extracting the UUID from the URI or maintaining a mapping table? it seems to me that matching on UUIDs is a more suitable approach here. or what am I missing?
In the context of a test-stage-prod deployment workflow, where the source site varies, it seems like matching on UUIDs is a more robust approach than having to support a changing prefix in the URI (namespace).
Yeah I hadn't really thought
Yeah I hadn't really thought through the fact that the URIs will be different between sites because mentally I was only thinking of the path. However you're right, we will probably need to extract and match on the UUIDs or possibly the path. In another issue Lin mentioned using to manage this, but I think that will get pretty messy and tough to maintain over time.
Deployment Sets
Yes, this makes a lot of sense from iPhone / Android / Non-Drupal Remote Machine development! The first and second options sound similar to an Service endpoint. The third option is requested by App developers all of the time.
Do you see the deployment sets as temporary or permanent?