
Buenas a todos.
A raiz de otro hilo sobre uso de herramientas de edición, surgió la propuesta de abrir un nuevo hilo sobre staging. Me pareción interesante, pero he decidido finalmente abrir uno sobre calidad e integración continua con un objetivo doble: orientar a las compañías o equipos de desarrollo que quieran implementar técnicas de calidad y reunir consejos de otros que hayan seguido caminos distintos, otras herramientas y otras metodologías.
Mi empresa, que tuvo una rápida expansión (de uno a doce programadores en poco más de un año), empezó a acumular problemas de integración de las partes desarrolladas por cada uno de los programadores. El escenario era el siguiente:
Los programadores commiteaban el código a medida que se iba desarrollando en el repositorio. No había control de calidad, más allá de las pruebas realizadas por el propio desarrollador. No había tests automáticos, ni estándares, ni separación de entornos. Desde la máquina local se vertía código a un servidor de pruebas, y de allí se desplegaba al entorno de producción. La comunicación era intermitente. No había control sobre lo que hacían tus compañeros, más allá del historial de subversion. No se puede negar que el desarrollo era realmente sencillo, pero los bugs, incoherencias y problemas de integración eran constantes.
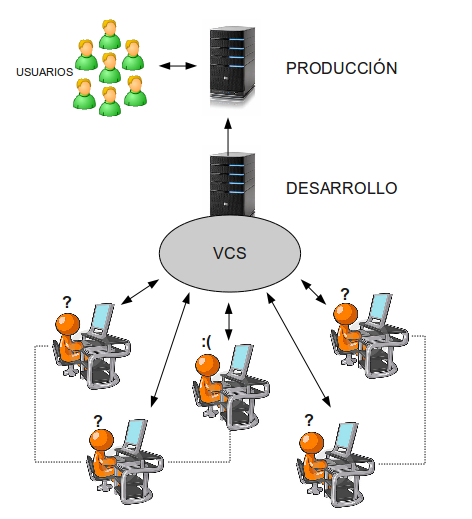
Cuando el departamento se hizo lo suficientemente grande, mejorar en este aspecto se convirtió en una prioridad. Se constituyó un equipo de QA (al principio formado por una sola persona, posteriormente se ampliaría a dos), que se encargaría de investigar, implantar sistemas de integración contínua, establecer metodologías y abrir brecha en la disciplina de los programadores. Estos fueron los pasos seguidos en dos meses, más o menos en orden de instauración:
Coding Standards
Se instaló la herramienta PHPCodeSniffer con el estándar de Drupal. Tuve que realizar algunos ajustes sobre el script y eliminar algunos warnings y errores demasiado estrictos. Se incrustó la herramienta en el hook pre-commit de subversion, de modo que actualmente es imposible commitear código que no cumpla con los estándares.
Doxygen
Instalamos Doxygen. Configuramos cron para que generase una documentación actualizada periódicamente en un website interno. El sniffer de coding standards se asegura de que toda función venga documentada.
SimpleTest. Script de vigilancia.
Hicimos una charla de formación interna sobre simpletest y se hizo mandatorio que todo el mundo desarrollase tests en sus módulos. Desarrollé un script que se invocaba desde el hook pre-commit y que hacía imposible commitear código si no se habían añadido un porcentaje suficiente de funciones al simpletest correspondiente. Establecimos el porcentaje al 70%, excluyendo hooks, preprocess y funciones de formularios (forms, submits y validates). Aunque esta imposición disciplinó a los programadores, con el paso del tiempo fue perdiendo utilidad. Ahora, con el desarrollo de pruebas unitarias y de integración asimilado por los desarrolladores, el script está desactivado.
Creación de una rama STABLE en el repositorio.
Dividimos el código en subversion en dos ramas; trunk y stable. Los desarrolladores iban depositando el código en trunk, y sólo en los despliegues (que ya eran planificados) se movía el código a la rama stable y se sincronizaba al entorno de producción.
Protocolo de despliegues.
El equipo se reunió y consensuó un protocolo de despliegues. Decidimos empezar a versionar y planificar las releases. Utilizando una herramienta de etiquetado (nosotros utilizamos jira, pero cualquiera vale), los desarrolladores asignan tareas realizadas a la versión a desplegar. Llegado el día del despliegue (semanal), QA se encarga de revisar cada uno de los bugs/desarrollos y comprobar el funcionamiento del sistema completo. Sólo QA está autorizado a desplegar código, y tiene autoridad para rechazar código que considere incorrecto.
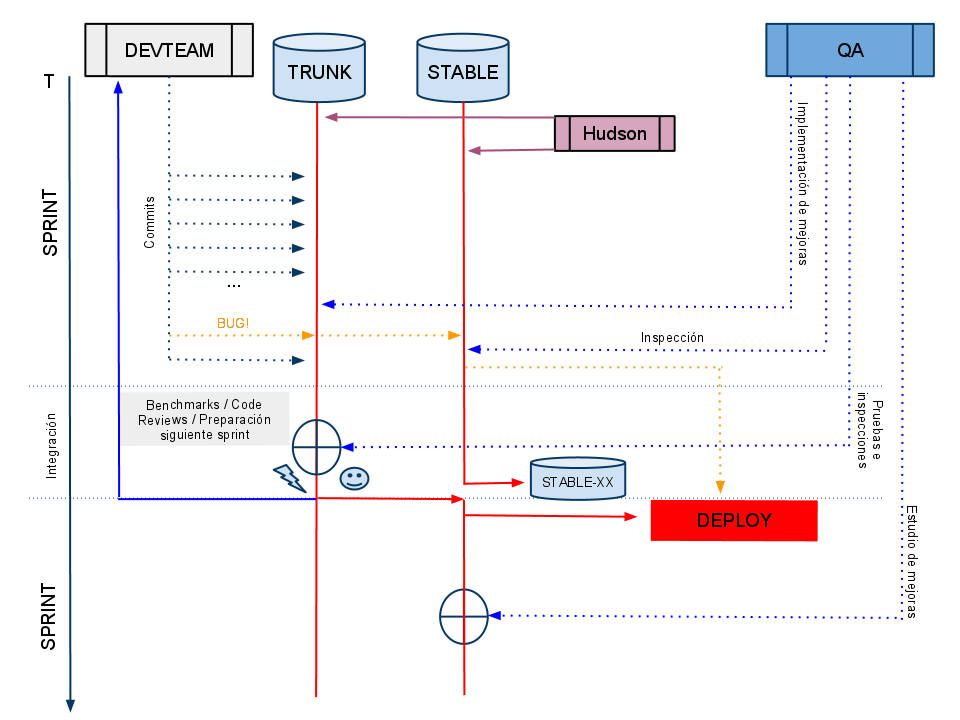
Automatización de Simpletest con Hudson.
Instalamos Hudson en el entorno de pruebas. Dividimos los tests en dos grupos: integración (DrupalWebTestCase) y unitarios (DrupalUnitTestCase). Hudson ejecuta constantemente tests tanto sobre la rama trunk como sobre stable. La rama stable recibe, también periódicamente, copias la base de datos de producción. Cuando Hudson descubre un error, envía un mail al equipo de desarrollo, y resolverlo se convierte en la primera prioridad del equipo.
Herramientas de medición de la calidad.
Instalamos PHPMD. Creamos un ruleset que se encargaba de medir tanto la complejidad ciclomática como la longitud de las funciones. Establecimos que el máximo de complejidad ciclomática era 15. Ninguna función podía superar ese umbral y ser desplegada. Instalamos también PHPCPD, una herramienta que permite detectar código duplicado.
Code refactoring.
Tenemos todavía miles de líneas de código antiguo por refactorizar. El code refactoring se organiza en ciclos. Se analiza una funcionalidad, se elabora un informe con los puntos oscuros o mejorables y se proponen mejoras. Posteriormente se realiza una cobertura completa de tests de integración a través de la interfaz (drupalGet y drupalPost) que sirva de anclaje seguro para futuras modificaciones. Una vez terminada la cobertura, se refactoriza el código y paralelamente se construyen los test unitarios. Esto permite una refactorización casi al 100% segura.
Tests de Selenium
Con el protocolo de despliegue elaboramos una checklist de pruebas de sistema que debíamos realizar manualmente para comprobar que todo estaba en orden. Funcionamiento de los foros, navegación de usuarios anónimos y registrados, interfaces de administración propias, etc... Como era una pesadez hacer todo esto a mano cada despliegue, utilizamos scripts de Selenium para automatizar la tarea.
Estas son las medidas que ahora mismo han sido adoptadas, hay otras todavía pendientes:
Code reviews.
Aunque actualmente QA se encarga de las code reviews para refactorizar el código, queremos instaurar cr como parte necesaria en el proceso de desarrollo. También queremos que sea algo participativo y responsabilidad del conjunto de desarrolladores, y no tarea de un organismo de inspección como ahora mismo.
Medición del rendimiento.
Del mismo modo que hudson se encarga de lanzar SimpleTest periódicamente, queremos elaborar un set de herramientas (o instalar ya existentes) que nos permitan controlar el rendimiento del site y encontrar problemas en la base de datos.
Con estas medidas hemos llegado a algo similar a esto:

El objetivo final es que QA desaparezca y los desarrolladores asuman de manera individual su parte proporcional en el control de la calidad.
Bueno, pues estas son las experiencias que hemos tenido en Aureka Internet. Espero que os sirvan y me gustaría recibir consejos, críticas y experiencias similares sobre este tema.
Un saludo,
Carles Climent.
| Attachment | Size |
|---|---|
| estado_inicial.png | 89.88 KB |
| estado_final.png | 113.24 KB |
| protocolodespliegue.png | 43.8 KB |
{kind=link}
{kind=link}
{kind=link}
Comments
El staging es una de nuestras
El staging es una de nuestras asignaturas pendientes.
Una de las cosas que no hemos resuelto es qué hacer con los ficheros de configuración (apache, mysql, php...). Aunque he encontrado dos versiones enfrentadas, ambas coinciden en algo: es útil mantener los cambios en los archivos de configuración en un repositorio.
En uno de los extremos, unos defienden que los desarrolladores deberían tener libertad para configurar su entorno de trabajo a su gusto. Otros, en cambio, defienden que no hay razón para personalizar rutas de apache, estructuras de directorio y settings de php y mysql. Incluso que las herramientas usadas por los desarrolladores deberían ser exactamente las mismas (editores, scripts, .bashrc...).
Así lo hacemos nosotros
Hola!
Al igual que vosotros, aquí también usamos el hook pre-commit de SVN para comprobar que el código que se envía cumpla los stándares de Drupal así como algunos más estrictos de la empresa. A parte, también integramos el SVN con un gestor de tareas (similar a open_atrium), de manera que al hacer commit se indique a qué tarea pertenece y desde la web se pueda ver qué commits se han hecho en qué tarea, junto a los cambios y la persona que lo haya subido, así como generar el comando necesario para hacer el deploy de desarrollo a stage y de stage a live. A parte de esto, cada commit también se envía a un par de personas que le echan un vistazo rápido para comprobar que no haya ninguna tontería en el código. Luego, cada tarea, pasa por ciertas etapas, entre las cuales hay una en que se pasa la tarea una persona que no tiene nada que ver con el desarrollo para que compruebe que los cambios cumplen con lo requerido.
Además, en la web que usamos, también se controla el tiempo. Cada vez que se añade un cambio, el autor pone el tiempo que le ha costado. De esta manera, podemos ver en qué se emplea más tiempo o podemos proporcionar reportes precisos al cliente del trabajo realizado.
Por otro lado, todavía no hemos empezado a usar los test unitarios, cosa que a veces se echa en falta.
Respecto al tema del staging, nosotros trabajamos desde local, cada uno con la configuración que quiera. Después tenemos un servidor de desarrollo común para todos los proyectos, un stage en función de las necesidades de cada proyecto, donde el cliente comprueba los cambios (exceptuando las veces que el cliente también cuenta con desarrolladores, en ese caso, se les suele dar acceso a dev y a veces, prescindimos del stage), y finalmente el live, los cuales no suelen compartir la configuración y muy pocas veces nos suele dar problemas.
Probablemente me deje muchas cosas en el tintero y algo haya puesto mal, ya que yo no me suelo encargar de esto, pero me imagino que algo podrés sacar en claro y haceros una idea.
Un saludo,
David.
Me apunto un par de ideas que
Me apunto un par de ideas que aún no tenemos y que me parecen muy interesantes.
Una de ellas ya nos la habíamos planteado pero aún no nos habíamos animado a implantarla, la de la asociación de commits al gestor de tareas. La manera en que la hemos resuelto de momento es exigir, en el ticket de la tarea, que el desarrollador indique qué archivos o funciones han sido modificadas.
La otra es la de el control del tiempo. Aunque nosotros no trabajamos para clientes externos, creo que incluir el tiempo invertido en una tarea ayuda para medir la productividad del equipo y mejorar las estimaciones futuras.
Por cierto, la idea del pre-commit de subversion nos la diste tú tras la primera drupalada en Valencia, así que desde aquí te decimos: muchas gracias!
Hola a
Hola a tod@s,
@carlescliment... estoy muy impresionado.
Aunque seguramente ya estabais al corriente Hudson ahora se llama Jenkins: http://www.dosideas.com/noticias/actualidad/943-hudson-pasa-a-llamarse-j... y la web oficial es: http://jenkins-ci.org/ que está hecha con Drupal :)
Post sobre el tema que quizá os sea útil: http://greenbeedigital.com.au/content/discovering-jenkins-and-increasing...
Un saludo,
Alessandro Mascherpa.
Para la medición de
Para la medición de rendimiento nosotros utilizamos jmeter.
Otra herramienta interesante a tener en cuenta, tanto para la fase final del desarrollo como para arreglar problemas "raros" es xhprof.
Oskar
Muchas gracias, oskar. Le
Muchas gracias, oskar. Le paso la info a nuestro compañero de sistemas.
En nuestro caso, para profiling, utilizamos xDebug y para monitorización del rendimiento Munin.
Estupendo despliegue de
Estupendo despliegue de información carlescliment, creo que es muy interesante que se hable del tema en la drupalcamp ;) http://2011.drupalcamp.es/
carlescliment es el módulo
carlescliment es el módulo coder una alternativa interesate a CodeSniffer ? o mejor liarse la manta ala cabeza y meterse de lleno con CodeSniffer?
Un saludo.
Oskar
Hola oskar, desde que puedes
Hola oskar,
desde que puedes invocar Coder desde Drush, es una alternativa sólida. Tendrás problemas si quieres integrarlo en el hook pre-commit, porque la salida de Drush es la misma haya problemas de estandarización o no. En este caso necesitarás capturar la salida de Drush con un script y devolver un código de error cuando sea necesario.
Es verdad que meterse con CodeSniffer es liarse la manta a la cabeza, pero una vez entendido cómo funciona permite ajustar las reglas existentes, o crear nuevas reglas de acuerdo con estándares de la empresa.
Si quieres una alternativa rápida y sin complicaciones, te recomiendo Coder. Si quieres probar CodeSniffer puedo pasarte nuestras modificaciones sobre el estandar original e instrucciones de instalación/configuración en subversion.
Un saludo.
Gracias carlesclimen. Ahora
Gracias carlesclimen.
Ahora mismo estamos en proceso de entrega de vario proyectos. Pero si que me gustaría agregar CodeSniffer a aquellos que vamos a comenzar nuevos. A la vuelta de vacaciones (me subo a Bilbo).
Lo que me preocupa es pedirle al diseñador gráfico-programador de fron-end que empiece con CodeSniffer.
Oskar
Al principio aquí todo el
Al principio aquí todo el mundo resoplaba y protestaba cuando tenía que confirmar código y el pre-commit lo rechazaba con 200 mensajes de error. Al cabo de dos semanas ya respetábamos inconscientemente los estándares mientras codificábamos. Te sorprenderá lo fácil que se adapta tu equipo. ¡Tu programador de front-end también! ;)
Carlsclimen. No digo que no,
Carlsclimen.
No digo que no, pero como tu has dicho, se necesita un periodo e transición, prefiero que hagamos el periodo de transición con proyectos que estamos comenzando, y no con aquellos que estamos a punto de finalizar.
De todas forma, estoy seguro que gritara, levantará los brazos, gesticulara, etc....
:D
Oskar
Para los usuarios de netbeans
Para los usuarios de netbeans hay un pluggin de PHPMD y codsniffer http://sourceforge.net/projects/phpmdnb/files/nbm/NetBeans-6.9.1/nb-phpm... ojo que luego viene el curro de configurarlos.
Hola Oskar, ¿has conseguido
Hola Oskar,
¿has conseguido configurarlo? Estuve un rato intentándolo sin éxito, y ni en StackOverflow parecen saber cómo hacerlo.
No he tenido tiempo, estamos
No he tenido tiempo, estamos de entrega estas dos semanas, y aun no he tenido tiempo.
Por ahora me quedo con coder hasta que tengamos un valle de curro.
Oska
Voy a echar
Voy a echarle un ojo a ese pluggin a ver que tal se menea .... Veo por otro comment que es difícil su conf vamos a ver que tal.
Comento en los proximos días.
C ya!
[at]killua99 ~~
hay también un pluggin para
hay también un pluggin para firefox xdebug helper, pero no lo he conseguido hacer funcionar.
Y con easy xdebug (otro pluggin de ff) http://blog.vidadel.es/2010/05/depurando-php-usando-netbeans-y-firefox/
Oskar
Promovido al grupo Spanish
Todas las consultas técnicas se deben realizar en el grupo Spanish y opcionalmente en algún grupo geográfico de interés.
Gracias por su colaboración.
--
[develCuy](http://steemit.com/@develcuy) on steemit
:)
Excelente Info, me aclara el panorama, solo una consulta no veo ningun timpo de manejo de tickets o herramienta para el manejo o control de bugs, alguna que pudieran recomendar.
Hola rosamaria, Lo que buscas
Hola rosamaria,
Lo que buscas es un gestor de proyectos, y en ese aspecto hay varias opciones. Como módulos de Drupal existe Storm. Otra solución basada en Drupal es el profile de Open Atrium. O también puedes emplear aplicaciones externas integradas con Drupal como Sugar CRM o CiviCRM.
Por la experiencia que tengo en este tema, la mejor suele ser hacer algo ha medida. No es algo excesivamente complicado usando algunos módulos como OG y Comment Driven.
Un saludo,
David.
Al principio usábamos
Al principio usábamos Basecamp, pero pronto se nos quedó pequeño. Desde hace tiempo utilizamos JIRA Studio, que es una herramienta de gestión integral muy completa y nada barata. Nos permite no solo trackear issues de una forma muy personalizada sino también otros extras como code reviews, métricas de SCRUM como burndowns, etc... Seguramente hay alternativas open-source gratuitas muy competitivas. Hace muchos años trabajé en una compañía que utilizaba TRAC, muy potente y personalizable. Quizá a estas alturas se haya quedado desfasado.
Desde que empezamos a adoptar SCRUM de una manera más o menos seria estoy dándome cuenta de que no hay como unas buenas pegatinas o tarjetas en una pared para las historias de usuario. Complementariamente, el tracking de bugs y de tarjetas en herramientas de etiquetado permiten una mayor coordinación a la hora de pasar las fases de testing, etc.
El documento empieza a estar un poco desfasado, quizá en unas semanas tenga que revisarlo.
Redmine y control de bugs
Hola, nosotros hemos tenido muy buen resultados utilizando Redmine (http://www.redmine.org/) que integra muy bien con Git y Subversion de tal manera que conforme que los developers solucionan bugs automaticamente conecta los cambios con el ticket. Tiene un interfaz elegante y rapido aunque al ser Ruby es un poco laborioso configurar el servidor para buen performance.
Tambien estamos probando con Pivotal Tracker (www.pivotaltracker.com) para el manejo de tickets y desde luego es mejor para la planificacion de proyectos pero para bugs opino que Redmine es mas efectivo.
Paul
Hola a todos, actualmente
Hola a todos,
actualmente estamos intentando llevar a cabo todos estos procesos de integración continua, pero a nuestro equipo nos aparece una duda importante, como sincronizar las bases de datos.
Pensábamos que quizás el drush sql-sync viniera a resolvernos estos problemas, pero no ha sido así ya que "pisa" una db con otra.
¿Que metodología utilizáis para tener sincronizadas las bases de datos?
un saludo,
Martín.
Martín González Robles
web: http://elsabrosista.com
email: martin.glez.robles@gmail.com
Unidad sobre OG para Drupal 7: http://www.forcontu.com/descarga/d7u66pdf
Hola Martín, Con
Hola Martín,
Con sincronización de bases de datos me imagino que te refieres a pasar los cambios de la base de datos del servidor de desarrollo al de producción. Este aspecto es una de las tareas pendientes de Drupal y, aunque ahora se está haciendo un esfuerzo para arreglarlo, hasta la nueva versión Drupal 8 no estará disponible. Mientras tanto, hay algunas soluciónes. Para replicar los cambios de configuración, como views, content types, CCK fields y demás, nosotros solemos utilizar el módulo Features, que te permite exportar a código gran parte de estos cambios.
Espero que esto te sirva de algo, si voy desencaminado, danos algún detalle más. Un saludo,
David.
Usar el install profile
Hola Martin,
Como bien dice David este es uno de los problemas mas pesadas de Drupal actualmente. Lo que nosotros hacemos es combinar features con la creacion de un install profile que construye el site de zero a completo. Utilizando drush se puede correr el perfil de instalacion desde un script, y de esta manera lo que consigues es crear el site nueva y de forma automatica en cada entorno cambiando solo los parametros correspondientes. Es una buena forma de trabajar con sites completamente nuevos - cada developer puede ir haciendo sus cambios al perfil de instalacion y cuando quieren ver como queda el resultado del equipo disparan una instalacion.
Nosotros utilizamos Hudson/Jenkins para manejar los deploys de tal manera que si, por ejemplo, quieres pasar tu entorno de desarollo a UAT simplemente seleccionas el tag que quieres deployar y el resto lo hace automaticamente a raiz de correr los scripts correspondientes. De manera similar puedes clonificar automaticamente la base de datos y archivos subidos por los usuarios del entorno de produccion a el de desarollo para investigar un bug o realizar un cambio antes de crear un nuevo tag y deployar el nuevo codigo con sus updates a UAT y posteriormente a produccion.
Un saludo,
Paul
Nosotros seguimos la línea de
Nosotros seguimos la línea de los install profiles mediante hook_updates() para la actualización de la base de datos. De hecho, nos es necesario hacerlo de este modo ya que utilizamos SimpleTest para los desarrollos. Los tests de integración de SimpleTest levantan una sandbox de la base de datos con instalaciones desde 0.
El principal problema viene para los editores de contenidos, que a menudo tienen que hacer doble trabajo, el que realizan en pre-producción y el definitivo en el entorno de producción. Tenemos pendiente investigar soluciones para Drupal para portar datos de un modo seguro de un entorno a otro, de momento no hemos encontrado ninguna opción satisfactoria.
@freshaspect interesante lo de desplegar desde Jenkins. Respecto a lo del clon de la base de datos, es imprescindible. Todas las pruebas deberían hacerse sobre bases de datos lo más actualizadas posible. En nuestro caso lo hacemos diariamente con un script que clona la base de datos de producción a un entorno de desarrollo. También es buena idea permitir la carga semiautomática de bases de datos del día en el entorno local del desarrollador.
Saludos.
Gracias a todos por vuestras
Gracias a todos por vuestras respuestas.
Según vuestros comentarios los pilares es trabajar con features, tener actualizaciones en el menor tiempo posible y tener un control del código con hudson/Jenkins y Simple Test.
Podemos tener por tanto actualizaciones del entorno de producción con desarrollos en torno a features, pero mientras probamos todos los cambios realizados, ¿qué nos aconsejáis, poner el sitio en mantenimiento (quizás algún día por los múltiples cambios de meses de desarrollo), o hay alguna forma de "servir" la aplicación bloqueando las inserciones en la base de datos?
El problema con los editores de contenido se ve agravado, ya que sería un proyecto muy vivo y el tiempo que se estaría en preproducción probando, cambiaría completamente la base de datos ya que cientos de usuarios estarían publicando contenidos…
El clonar la base de datos de producción a dev, ¿sería de alguna tabla en concreto o de toda la db directamente?
Saludos,
Martín
Martín González Robles
web: http://elsabrosista.com
email: martin.glez.robles@gmail.com
Unidad sobre OG para Drupal 7: http://www.forcontu.com/descarga/d7u66pdf
Yo creo que lo mejor sería no
Yo creo que lo mejor sería no tener desarrollos que se estiendan tanto en el tiempo, y por experiencia.
Nosotros tuvimos que parar una revista digital viernes por la tarde, sabado todo el día y domingo todo el día asumiendo que a lo sumo se perderían los comentarios de esos tres días si teníamos que retroceder.
Mi recomendación, actualizaciones "de apoco", y si no se puede, evitar que afecten al contenido, si hay que tener el contenido sincronizado, antes de que empiecen los redactores a trabajar los entornos de desarrollo que tengan una replica de la bbdd de los redactores y a estos ir configurando aquellas cosas (nodequeue y similares) que no se pueden exportar.
Oskar
Realizar todos los cambios que se pueda atraves de codigo
El principio que nosotros aplicamos es minimizar todo lo que podamos los cambios o actualizaciones a un site que se tengan que hacer durante la utilizacion de la misma. El proceso que solemos aplicar es:
A veces resulta un poco pesado este proceso y no cabe duda que hay algunos cambios que son mejores realizados atraves del interfaz de administracion. Es cuestion de analizar los riesgos y elegir la mejor ruta. Lo bueno de usar update hooks es que tienes el cambio bajo control de versiones y si algo no va bien se puede corregir rapido y probar de nuevo.
Paul
Investigando un poco he dado
Investigando un poco he dado con un módulo que quizás ayude a mis dudas planteadas, aunque aún me falta probarlo.
Se trata del módulo uuid_features y di con el leyendo este blog
Otra duda que tengo con las features, es si hay alguna forma de exportar la configuración de un módulo o no.
Un saludo,
Martín
Martín González Robles
web: http://elsabrosista.com
email: martin.glez.robles@gmail.com
Unidad sobre OG para Drupal 7: http://www.forcontu.com/descarga/d7u66pdf
La exportación de la
La exportación de la configuración del módulo en principio se puede hacer si la configuración se almacena en al tabla de variables de Drupal. Features permite declarar que variables (de la tabla de variables de Drupal) se incluyen en una feature. De esta forma, si declaras en al feature las variables de configuración del módulo teóricamente podrías exportar la configuración de dicho módulo. Sin embargo, te puedes encontrar con problemas. Por ejemplo, si un módulo usa una taxonomía en su configuración normalmente guardará el identificador de la taxonomía. Pero claro, ese identificador no tendrá por que ser el mismo en dos drupales diferentes (lo normal es que no lo sean, que directamente no exista).
Es un problema general con los identificadores autoincrementados de Drupal, y este módulo (uuid_features) trata de solventar. Como no lo he mirado demasiado no te puedo decir si soluciona completamente el problema o no.
El problema de las taxonomías
El problema de las taxonomías puede resolverse si dichas taxonomías se crean programáticamente (taxonomy_save_vocabulary() y taxonomy_save_term()) durante la instalación del módulo. Una vez creados se almacenan sus IDs con variable_set(). Las referencias en los módulos a IDs de las taxonomías pueden entonces rescatarse allí donde se necesiten con variable_get().
Del mismo modo, un módulo puede autoconfigurar sus parámetros iniciales sin necesidad de utilizar otras herramientas.
Claro, esa es buena solución
Claro, esa es buena solución en los casos en los que es el propio módulo quien controla la taxonomía, pero yo me refiero a los módulos que en su configuración necesitan que el usuario les indique una taxonomía a usar (por que el módulo trabaja sobre una taxonomía ya creada, por una que genere el propio módulo). En cualquier caso era un ejemplo para ilustrar la problemática de los identificadores y como meter variables en features no soluciona totalmente el asunto de la configuración de los módulos.
Bueno días, Acabo de hacer
Bueno días,
Acabo de hacer una prueba sencilla y si que he podido pasar contenido por feature de un entorno a otro.
Los pasos han sido descargar y activar en ambos entornos los módulos uuid y uuid_features. Si el tipo de contenido requiere de más módulos también deberán ser activados en el otro entorno.
En admin/settings/uuid configuramos que tipos de contenidos queremos que tengan uuid (o usuarios, taxonomías o comentarios).
Creamos un contenido del tipo seleccionado.
Si miramos la base de datos, veremos que en la tabla uuid_node tendremos un nuevo registro.
Ahora solo nos falta crear la feature, donde tendremos un nuevo componente para seleccionar, content, donde nos aparecerán todos los contenidos que tengan uuid (en admin/settings/uuid tenemos la opción de actualizar la tabla de uuid con los contenidos que ya había en el portal antes de activar el uuid para el tipo de contenido, pulsando en create missing uuids).
A ver si encontramos la forma de conseguir migrar las configuraciones de módulos de un entorno a otro.
Un saludo,
Martín
Martín González Robles
web: http://elsabrosista.com
email: martin.glez.robles@gmail.com
Unidad sobre OG para Drupal 7: http://www.forcontu.com/descarga/d7u66pdf